# General
library(tidyverse)
# Webscraping
library(rvest)
library(RSelenium)
# Geo data
library(tidygeocoder)
library(leaflet)
library(rnaturalearth)
library(sf)
# NLP
library(udpipe)
library(textrank)
library(wordcloud)
# Cleaning
library(stringr)
# Additional functions presented at the end of the post
source('scraping_functions.R') Il y a quelques semaines, j’ai commencé à chercher un poste de data scientist dans l’industrie. Mes premières actions ont été de :
- Regarder les offres d’emploi sur des sites comme Indeed
- Mettre à jour mon CV
Après avoir lu de nombreuses annonces et travaillé plusieurs heures sur mon CV, je me suis demandé si je pouvais optimiser ces étapes avec R et Data Science. J’ai donc décidé de scraper Indeed et d’analyser les données des offres de data science pour :
- Obtenir une vue d’ensemble visuelle des informations essentielles comme la localisation, le type de contrat, la fourchette salariale pour un grand nombre d’annonces
- Optimiser mon CV pour le scan ATS avec des mots-clés précis
Chargement des bibliothèques
La première étape est d’importer plusieurs packages :
Collecter les données avec le web scraping
Au début de ce projet, j’utilisais read_html() de rvest pour accéder et télécharger la page web d’Indeed. Cependant, les pages Indeed sont protégées par un logiciel anti-scraping qui bloquait toutes mes demandes, même si le scraping n’est pas interdit sur les pages qui m’intéressent (j’ai vérifié la page robots.txt).
C’est pourquoi j’ai décidé d’accéder aux pages avec Rselenium qui permet d’exécuter un navigateur sans tête (“headless”). On commence par naviguer vers la page correspondant aux résultats de recherche des offres de Data Scientist en France :
url = "https://fr.indeed.com/jobs?q=data%20scientist&l=France&from=searchOnHP"
# Headless Firefox browser
exCap <- list("moz:firefoxOptions" = list(args = list('--headless')))
rD <- rsDriver(browser = "firefox", extraCapabilities = exCap, port=1111L,
verbose = F)
remDr <- rD$client
# Navigate to the url
remDr$navigate(url)
# Store page source
web_page <- remDr$getPageSource(header = TRUE)[[1]] %>% read_html()Pour scraper une information spécifique sur une page web, voici les étapes à suivre :
- Trouver l’élément/texte/donnée que vous souhaitez scraper sur la page web.
- Trouver le xpath ou le sélecteur CSS associé en utilisant l’outil de développement de Chrome ou Firefox (tutoriel ici !).
- Extraire l’élément avec
html_element()en indiquant le xpath ou le sélecteur CSS. - Transformer les données en texte avec
html_text2(). - Nettoyer les données si nécessaire.
Voici l’exemple avec le nombre d’offres de Data Scientist listées en France :
web_page %>%
html_element(css = "div.jobsearch-JobCountAndSortPane-jobCount") %>% # selecting with css
html_text2() %>% # Transform to text
str_remove_all("[^0-9.-]") %>% # Clean the data to only get numbers
substr(start = 2, stop = 8) %>%
as.numeric()Pour l’instant, on ne peut scraper les données que de la première page. Cependant, je suis intéressé par toutes les offres d’emploi et j’ai besoin d’accéder aux autres pages ! Après avoir navigué sur les 3 premières pages des offres, j’ai remarqué un modèle dans l’URL (valide au moment de l’écriture), ce qui signifie qu’avec une seule ligne de code, je peux produire une liste contenant les URL des 40 premières pages.
Une fois la liste obtenue, il ne reste plus qu’à boucler sur toutes les URL avec un délai (bonne pratique pour le web scraping), collecter les données et les nettoyer avec des fonctions personnalisées (à la fin de l’article) :
# Creating URL link corresponding to the first 40 pages
base_url = "https://fr.indeed.com/jobs?q=data%20scientist&l=France&start="
url_list <- c(url, paste0(base_url, as.character(seq(from=10, to=400, by=10))))
# Looping through the URL list
res <- list()
for(i in 1:length(url_list)){
# Navigate to the URL
remDr$navigate(url_list[i])
# Store page source
web_page <- remDr$getPageSource(header = TRUE)[[1]] %>% read_html()
# Job title
job_title <- web_page %>%
html_elements(css = ".mosaic-provider-jobcards .result") %>%
html_elements(css = ".resultContent") %>%
html_element("h2") %>%
html_text2() %>%
str_replace(".css.*;\\}", "")
# URL for job post
job_url <- web_page %>%
html_elements(css = ".mosaic-provider-jobcards .result")%>%
html_elements(css = ".resultContent") %>%
html_element("h2") %>%
html_element("a") %>%
html_attr('href') %>%
lapply(function(x){paste0("https://fr.indeed.com", x)}) %>%
unlist()
# Data about company
company_info <- web_page %>%
html_elements(css = ".mosaic-provider-jobcards .result")%>%
html_elements(css = ".resultContent")%>%
html_element(css = ".company_location")%>%
html_text2() %>%
lapply(FUN = tidy_comploc) %>% # Function to clean the textual data
do.call(rbind, .)
# Data about job description
job_desc <- web_page %>%
html_elements(css = ".mosaic-provider-jobcards .result")%>%
html_element(css =".slider_container .jobCardShelfContainer")%>%
html_text2() %>%
tidy_job_desc() # Function to clean the textual data related to job desc.
# Data about salary (when indicated)
salary_hour <- web_page %>%
html_elements(css = ".mosaic-provider-jobcards .result .resultContent")%>%
html_element(css = ".salaryOnly") %>%
html_text2() %>%
lapply(FUN = tidy_salary) %>% # Function to clean the data related to salary
do.call(rbind, .)
# Job posts in the same format
final_df <- cbind(job_title, company_info, salary_hour, job_desc, job_url)
colnames(final_df) <- c("Job_title", "Company", "Location", "Rating", "Low_salary", "High_salary", "Contract_info", "Job_desc", "url")
res[[i]] <- final_df
# Sleep 5 seconds, good practice for web scraping
Sys.sleep(5)
}
# Gather all the job post in a tibble
final_df <- as_tibble(do.call("rbind", res))
# Final data cleaning
final_df <- final_df %>%
mutate_at(c("Rating", "Low_salary", "High_salary"), as.numeric)
# Clean job title
final_df$Job_title_c <- clean_job_title(final_df$Job_title)
final_df$Job_title_c <- as.factor(final_df$Job_title_c)On a maintenant un jeu de données propre ! Voici un exemple tronqué des 5 premières lignes :
| Job_title | Company | Location | Rating | Low_salary | High_salary | Contract_info | Job_desc | Job_type | Job_title_c |
|---|---|---|---|---|---|---|---|---|---|
| Data Scientist junior (H/F) | Kea & Partners | 92240 Malakoff | NA | 3750 | 4583 | CDI +2 | Travail en journée +1 | Plusieurs postes à pourvoirMaitrise de Python et des packages de data science. 1er cabinet européen de conseil en stratégie à devenir Société à Mission, certifiés B-Corp depuis 2021*,… | Présentiel | data scientist junior |
| Data Scientist (F ou H) | SNCF | Saint-Denis (93) | 3.9 | NA | NA | CDI | Le développement informatique (C, C++, Python, Azure, …). Valider et recetter les phases des projets. Travailler avec des méthodes agiles avec les équipes et… | Présentiel | data scientist |
| Data Scientist (H/F) (IT) | Yzee Services | Paris (75) | 3.3 | 2916 | 3750 | Temps plein | Recueillir, structurer et analyser les données pertinentes pour l'entreprise (activité liée à la relation client, conseil en externe). | Présentiel | data scientist |
| Data Scientist H/F | Natan (SSII) | Paris (75) | NA | 4583 | 5833 | CDI +1 | Travail en journée | Plusieurs postes à pourvoirVous retrouverez une *ESN ambitieuse portée par le goût de l’excellence.*. Au sein du département en charge d'automatisation transverse des besoins de la… | Présentiel | data scientist |
| Data Scientist Junior H/F / Freelance | karma partners | Roissy-en-Brie (77) | NA | 400 | 550 | Temps plein +1 | Le profil recherché est un profil junior (0-2 ans d'expérience) en data science, avec une appétence technique et des notions d'architecture logicielle et de… | Présentiel | data scientist junior |
Visualisation des salaires proposés
Voyons si on peut obtenir quelques informations sur les offres de jobs en data science en réalisant quelques représentations graphiques. La première chose que je voulais savoir, c’était combien les entreprises étaient prêtes à payer pour recruter un candidat en data science. J’ai donc décidé de réaliser quelques graphiques sur la plage de salaires en fonction de l’entreprise et du titre du poste.
Attention !
Les graphiques suivants doivent être pris avec des pincettes, car ils affichent un petit échantillon des données. En effet, le salaire n’était listé que pour 14% des annonces. Les tendances ou informations dans ces graphiques peuvent ne pas être représentatives des entreprises n’ayant pas indiqué leur salaire proposé.
Salaire par entreprise
Le graphique suivant montre les revenus mensuels proposés par certaines entreprises (toutes les entreprises ne listent pas leur salaire proposé) :
# Function to make euro X scale
euro <- scales::label_dollar(
prefix = "",
suffix = "\u20ac",
big.mark = ".",
decimal.mark = ","
)
final_df %>%
filter(Low_salary > 1600) %>% # To remove internships and freelance works
select(Company, Low_salary, High_salary) %>%
group_by(Company) %>%
summarize_if(is.numeric, mean) %>%
mutate(Mean_salary = rowMeans(cbind(Low_salary, High_salary), na.rm = T),
Company = fct_reorder(Company, desc(-Mean_salary))) %>%
ggplot(aes(x = Company)) +
geom_point(aes(y = Mean_salary), colour = "#267266") +
geom_linerange(aes(ymin = Low_salary, ymax = High_salary)) +
geom_hline(aes(yintercept = median(Mean_salary)), lty=2, col='red', alpha = 0.7) +
scale_y_continuous(labels = euro) +
ylab("Monthly income") +
xlab("") +
coord_flip() +
theme_bw(base_size = 8)
La médiane des salaires mensuels est d’environ 3700 euros. Comme vous pouvez le constater, les salaires peuvent varier considérablement selon l’entreprise. Cela est en partie dû au fait que je n’ai pas fait de distinction entre les différents types de postes en data science (data scientist, data analyst, data engineer, senior ou lead).
Salaire par titre de poste
On peut tracer le même graphique, mais au lieu de regrouper par entreprise, on va regrouper par titre de poste :
final_df %>%
filter(Low_salary > 1600) %>% # To remove internships and freelance works
select(Job_title_c, Low_salary, High_salary, Job_type) %>%
group_by(Job_title_c) %>%
summarize_if(is.numeric, ~ mean(.x, na.rm = TRUE)) %>%
mutate(Mean_salary = rowMeans(cbind(Low_salary, High_salary), na.rm = T),
Job_title_c = fct_reorder(Job_title_c, desc(-Mean_salary))) %>%
ggplot(aes(x = Job_title_c, y = Mean_salary)) +
geom_point(aes(y = Mean_salary), colour = "#267266") +
geom_linerange(aes(ymin = Low_salary, ymax = High_salary)) +
#geom_label(aes(label = n, Job_title_c, y = 1500), data = count_df) +
scale_y_continuous(labels = euro) +
theme_bw(base_size = 12) +
xlab("") +
ylab("Monthly Income") +
coord_flip()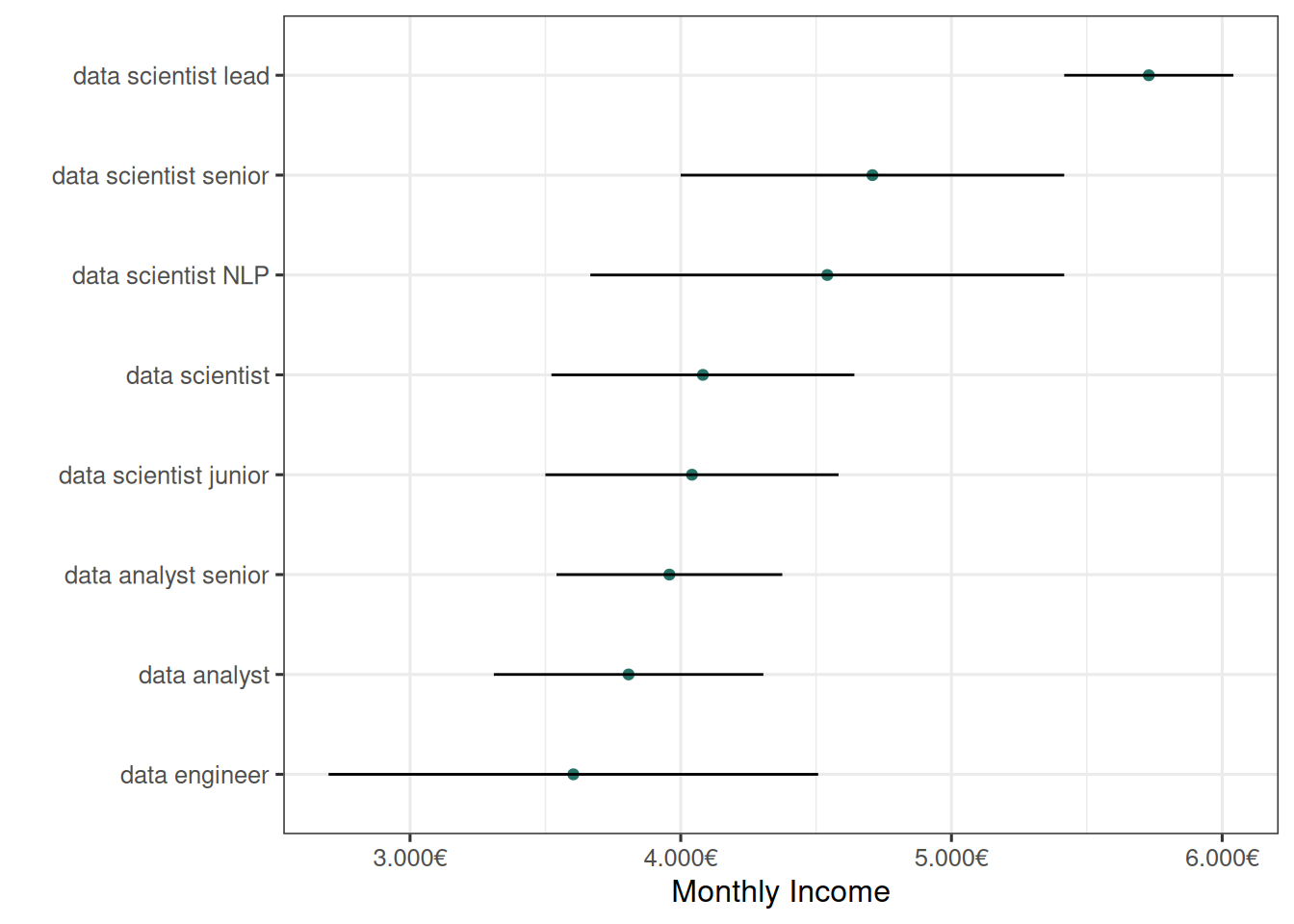
On remarque clairement les différences de salaires proposés en fonction du titre de poste : les data scientists semblent gagner légèrement plus en moyenne que les data analysts. Les entreprises semblent également proposer des salaires plus élevés pour les postes avec plus de responsabilités ou nécessitant plus d’expérience (senior, lead).
Salaire en fonction de la localisation : télétravail complet, hybride, sur site ?
Enfin, on peut tracer les salaires en fonction de la localisation (télétravail complet, hybride, sur site) pour voir si cela a un impact :
# Tidy the types and locations of listed jobs
final_df <- tidy_location(final_df)
count_df <- count(final_df %>% filter(Low_salary > 1600), Job_type)
final_df %>%
filter(Low_salary > 1600) %>%
drop_na(Location) %>%
mutate(Mean_salary = rowMeans(cbind(Low_salary, High_salary), na.rm = T),
Job_type = as.factor(Job_type)) %>%
ggplot(aes(x = Job_type, y = Mean_salary)) +
geom_boxplot(na.rm = TRUE) +
geom_label(aes(label = n, Job_type, y = 5500), data = count_df) +
scale_y_continuous(labels = euro) +
theme_bw(base_size = 12) +
xlab("Job Type") +
ylab("Income")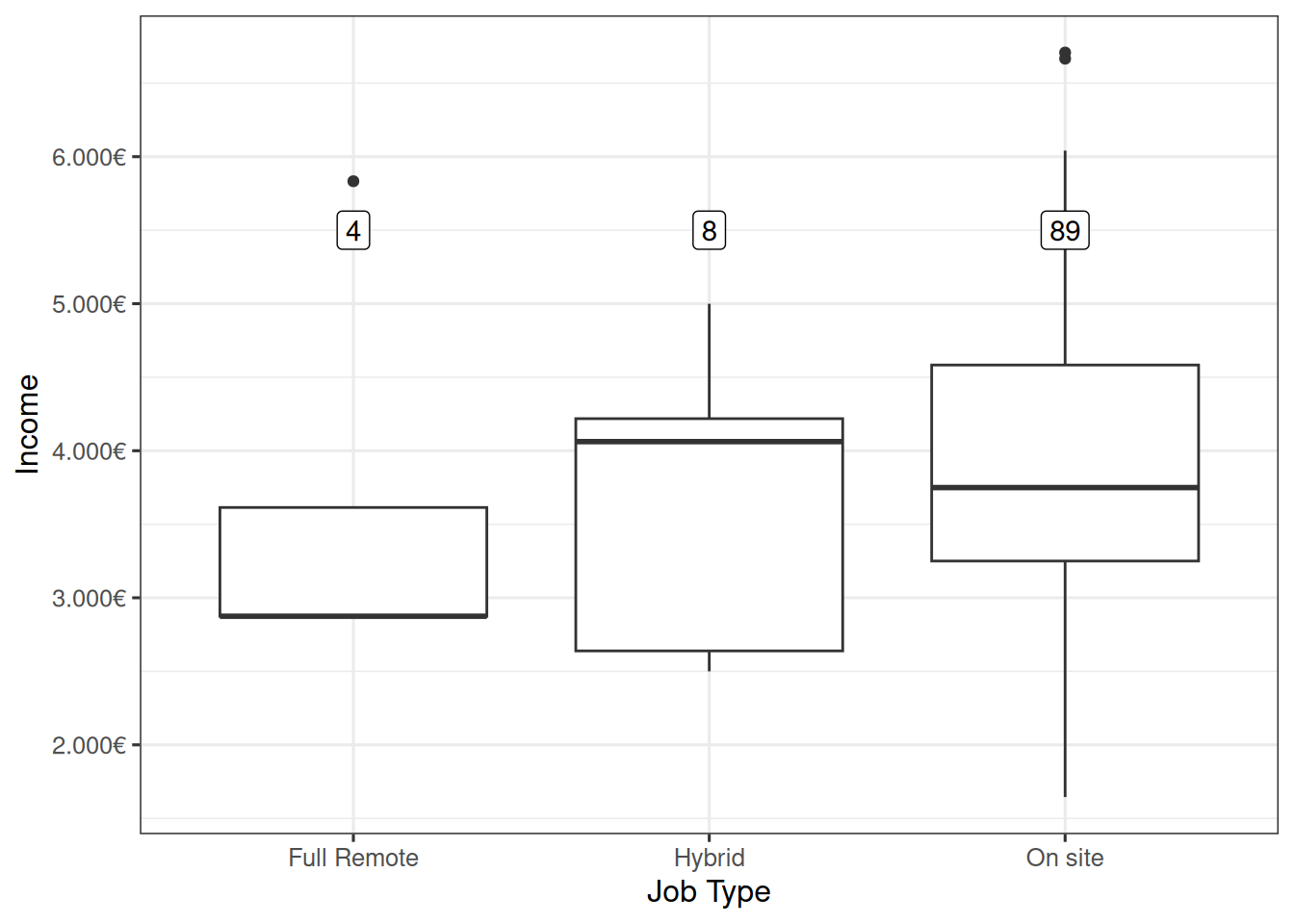
Il est à noter que la plupart des emplois proposés en France sont des emplois sur site. Le salaire médian pour ce type de postes est légèrement inférieur à celui des emplois hybrides. La distribution des salaires pour les emplois en télétravail complet et hybrides doit être interprétée avec prudence car elle ne concerne que 12 offres d’emploi.
Cartographie des lieux des emplois
Lors de ma recherche d’emploi, j’étais frustré de ne pas voir une carte géographique regroupant les lieux de tous les emplois proposés. Une telle carte pourrait m’aider considérablement dans ma recherche. Faisons-la !
Tout d’abord, on doit nettoyer et homogénéiser les lieux pour toutes les offres d’emploi. À cette fin, j’ai créé une fonction personnalisée (tidy_location()) qui inclut plusieurs fonctions de stringr. Vous pouvez trouver plus de détails sur cette fonction à la fin de ce post. Elle renvoie le lieu sous ce format : [Ville]([Code postal]). Même si tous les lieux ont été homogénéisés, ils ne peuvent pas être directement tracés sur une carte (on a besoin de la longitude et de la latitude). Pour obtenir la latitude et la longitude à partir du nom de la ville et du code postal, j’ai utilisé la fonction geocode() du package tidygeocoder.
# Extract coordinates from town name
final_df <- final_df %>%
mutate(Loc_tidy_fr = paste(Loc_tidy, 'France')) %>%
geocode(Loc_tidy_fr, method = 'arcgis', lat = latitude , long = longitude) %>%
select(- Loc_tidy_fr)Distribution des emplois en Data Science en France
On peut maintenant représenter le nombre d’emplois en Data Science par département :
# Map of France from rnaturalearth package
france <- ne_states(country = "France", returnclass = "sf") %>%
filter(!name %in% c("Guyane française", "Martinique", "Guadeloupe", "La Réunion", "Mayotte"))
# Transform location to st point
test <- st_sf(final_df, geom= lapply(1:nrow(final_df), function(x){st_point(c(final_df$longitude[x],final_df$latitude[x]))}))
st_crs(test) <- 4326
# St_join by departments
joined <- france %>%
st_join(test, left = T)
# Custom breaks for visual representation
my_breaks = c(0, 2, 5, 10, 30, 50, 100, 260)
joined %>%
mutate(region=as.factor(name)) %>%
group_by(region) %>%
summarize(Job_number=n()) %>%
mutate(Job_number = cut(Job_number, my_breaks)) %>%
ggplot() +
geom_sf(aes(fill=Job_number), col='grey', lwd=0.2) +
scale_fill_brewer("Job number",palette = "GnBu") +
theme_bw()
Il est vraiment intéressant de constater que la répartition des emplois est assez hétérogène en France. La majorité des emplois sont concentrés dans quelques départements qui abritent une grande ville. Cela est attendu, car la plupart des emplois sont proposés par de grandes entreprises souvent installées à proximité des grandes villes.
Carte interactive
On peut assii aller plus loin et tracer une carte interactive avec leaflet, ça nous permet de rechercher dynamiquement une offre d’emploi :
# Plot leaflet map
final_df %>%
mutate(pop_up_text = sprintf("<b>%s</b> <br/> %s",
Job_title, Company)) %>% # Make popup text
leaflet() %>%
setView(lng = 2.36, lat = 46.31, zoom = 5.2) %>% # Center of France
addProviderTiles(providers$CartoDB.Positron) %>%
addMarkers(
popup = ~as.character(pop_up_text),
clusterOptions = markerClusterOptions()
)Analyser les descriptions d’emploi
De nos jours, la plupart des CV sont scannés et interprétés par un système de suivi des candidatures (ATS). Pour faire simple, ce système recherche des mots-clés dans votre CV et évalue la correspondance avec l’offre d’emploi pour laquelle vous postulez. Il est donc important de décrire vos expériences avec des mots-clés spécifiques pour améliorer vos chances d’accéder à l’étape suivante du processus de recrutement.
Mais quels mots-clés devrait-on inclure dans mon CV ? Répondons à cette question en analysant les descriptions des offres d’emploi de data scientist.
Télécharger et nettoyer chaque description d’emploi
Tout d’abord, on télécharge la description complète de chaque offre en naviguant à travers toutes les URL listées dans notre tableau. On nettoye et homogénéise la description avec une fonction personnalisée :
# Loop through all the URLs
job_descriptions <- list()
pb <- txtProgressBar(min = 1, max = length(final_df$url), style = 3)
for(i in 1:length(final_df$url)){
remDr$navigate(final_df$url[i])
web_page <- remDr$getPageSource(header = TRUE)[[1]] %>% read_html()
job_descriptions[[i]] <- web_page %>%
html_elements(css = ".jobsearch-JobComponent-description") %>%
html_text2()
Sys.sleep(2)
setTxtProgressBar(pb, i)
}
# Gathering in dataframe
job_descriptions <- as.data.frame(do.call("rbind", job_descriptions))
names(job_descriptions) <- c("Description")
# Binding to same table:
final_df <- cbind(final_df, job_descriptions)
# Homogenize with custom function
final_df$Description_c <- lapply(final_df$Description, function(x){clean_job_desc(x)[[2]]})
final_df$Language <- textcat::textcat(final_df$Description)Procédure d’annotation avec le package udpipe
Cette partie est inspirée de cet article.
Maintenant que les descriptions de tous les emplois listés sont importées et pré-nettoyées, on peut annoter les données textuelles avec le package udpipe. Ce package contient des fonctions et des modèles qui permettent de réaliser la tokenisation, la lemmatisation et l’extraction de mots-clés.
On restreigne d’abord cette analyse aux offres d’emploi de data scientist rédigées en français, puis on annote toutes les descriptions :
# Restricting the analysis to Data scientist post written in french
desc_data_scientist <- final_df %>%
filter((Job_title_c == "data scientist") & (Language == "french")) %>%
select(Description_c)
ud_model <- udpipe_download_model(language = "french") # Download the model if necessary
ud_model <- udpipe_load_model(ud_model$file_model)
# Annotate the descriptions
x <- udpipe_annotate(ud_model, x = paste(desc_data_scientist, collapse = " "))
x <- as.data.frame(x)Les noms les plus courants
On peut visualiser les mots les plus utilisés dans les offres d’emploi de data scientist rédigées en français :
stats <- subset(x, upos %in% "NOUN")
stats <- txt_freq(x = stats$lemma)
stats %>%
top_n(50, freq) %>%
mutate(key = as.factor(key),
key = fct_reorder(key, freq)) %>%
ggplot(aes(x = key, y = freq)) +
geom_bar(stat = 'identity') +
coord_flip() +
ylab("Most common nouns") +
theme_bw()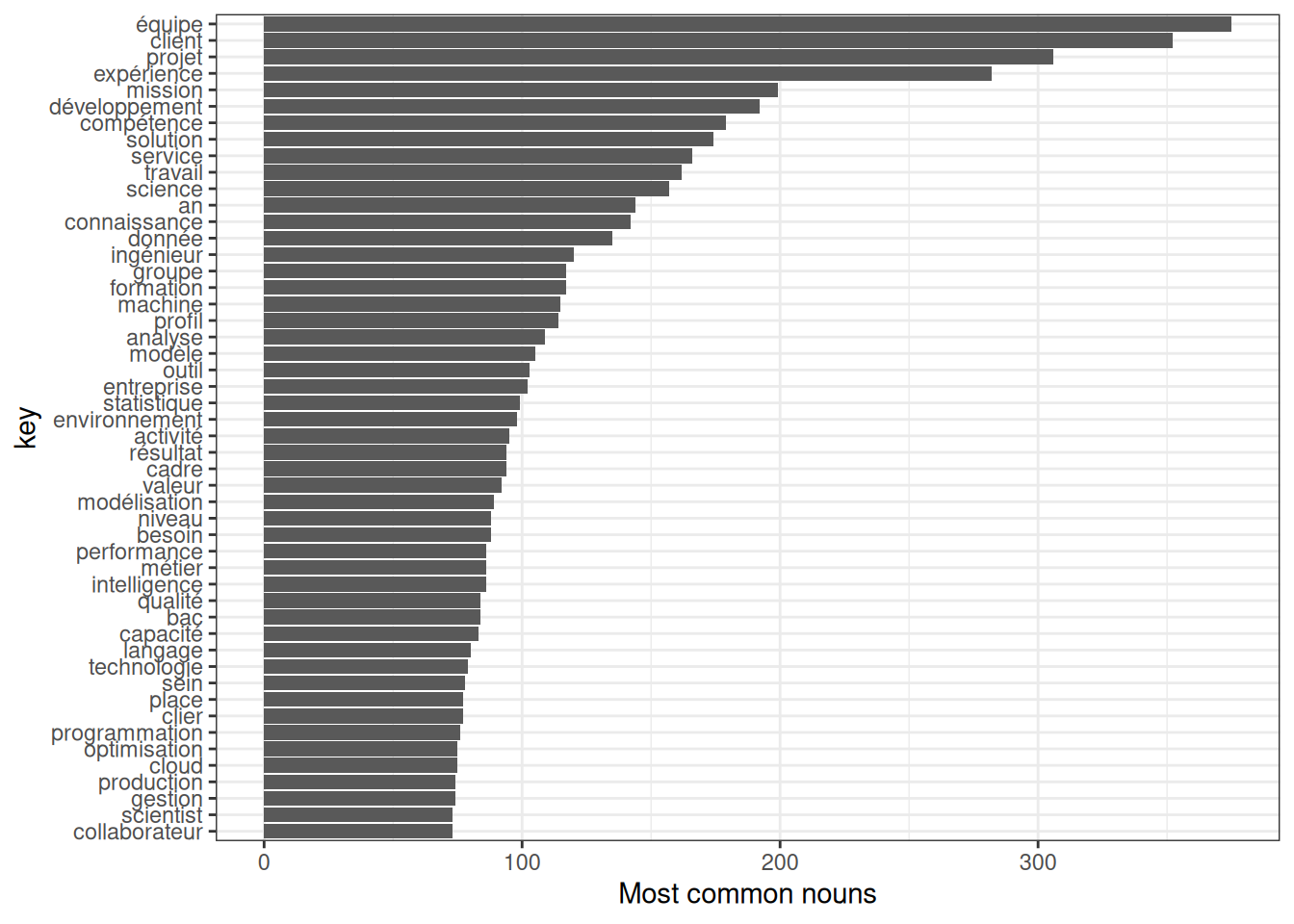
Bien que cela nous donne une idée des mots à inclure, ce n’est pas très informatif car les mots-clés sont souvent composés de deux mots ou plus.
Extraction des mots-clés pour la rédaction de CV
Il existe plusieurs méthodes implémentées dans udpipe pour extraire les mots-clés d’un texte. Après avoir testé plusieurs méthodes, j’ai sélectionné l’extraction automatique rapide des mots-clés (RAKE) qui me donne les meilleurs résultats :
stats <- keywords_rake(x = x,
term = "token",# Search on token
group = c("doc_id", "sentence_id"), # On every post
relevant = x$upos %in% c("NOUN", "ADJ"), # Only among noun and adj.
ngram_max = 2, n_min = 2, sep = " ")
stats <- subset(stats, stats$freq >= 5 & stats$rake > 3)
stats %>%
arrange(desc(rake)) %>%
head() keyword ngram freq rake
1 intelligence artificielle 2 9 9.368889
2 tableaux bord 2 5 8.504274
3 formation supérieure 2 5 8.374725
4 modèles prédictifs 2 15 7.581294
5 force proposition 2 6 7.190238
6 production échelle 2 5 7.034038wordcloud(words = stats$keyword, freq = stats$freq, min.freq = 3,
max.words=100, random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"), scale = c(2.5, .5))
On peut voir que cette méthode a sélectionné des mots-clés importants en français liés au poste de data scientist ! Dans les premières positions, on trouve les mots-clés : “intelligence artificielle”, “tableaux de bord”, “enseignement supérieur”, “modèle prédictif”. Il vaut mieux vérifier si ces mots apparaissent sur mon CV !
Conclusion
J’espère vous avoir convaincu qu’il est possible d’optimiser votre recherche d’emploi avec la Data Science !
Si cet article vous a intéressé et que vous êtes à la recherche d’un nouveau Data Scientist, n’hésitez pas à me contacter par mail car je suis actuellement en recherche d’emploi en France (hybride, remote) ou en Europe (remote).
Fonctions personnalisées pour nettoyer les données extraites de la page web
Ces fonctions utilisent plusieurs méthodes telles que les expressions régulières, les mots vides et les instructions conditionnelles pour nettoyer les données textuelles.
library(rvest)
library(stringr)
library(httr)
library(tidystopwords)
library(textcat)
# Function to tidy the data related to the company
tidy_comploc <- function(text){
lst <- str_split(text, pattern = "\n", simplify =T)
ext_str <- substr(lst[1], nchar(lst[1])-2, nchar(lst[1]))
res <- suppressWarnings(as.numeric(gsub(',', '.', ext_str)))
lst[1] <- ifelse(is.na(res), lst[1], substr(lst[1], 1, nchar(lst[1])-3))
lst[3] <- res
t(as.matrix(lst))
}
# Function to tidy the short job description provided with the job post
tidy_job_desc <- function(text){
stopwords <- c("Candidature facile", "Employeur réactif")
text <- str_remove_all(text, paste(stopwords, collapse = "|"))
stopwords_2 <- "(Posted|Employer).*"
text <- str_remove_all(text, stopwords_2)
text
}
# Function to tidy the salary data if provided
tidy_salary <- function(text){
if(is.na(text)){
others <- NA
sal_low <- NA
sal_high <- NA
}else{
text <- str_split(text, "\n", simplify = T)
others <- paste(text[str_detect(text, "€", negate = T)], collapse = " | ")
sal <- text[str_detect(text, "€", negate = F)]
if(rlang::is_empty(sal)){
sal_low <- NA
sal_high <- NA
}else{
range_sal <- as.numeric(str_split(str_remove_all(str_replace(sal, "à", "-"), "[^0-9.-]"), "-", simplify = TRUE))
sal_low <- sort(range_sal)[1]
sal_high <- sort(range_sal)[2]
if(str_detect(sal, "an")){
sal_low <- floor(sal_low/12)
sal_high <- floor(sal_high/12)
}
}
}
return(c(as.numeric(sal_low), as.numeric(sal_high), others))
}
# Function to tidy the location of the job (Remote/Hybrid/Onsite) + homogenize
# location and zip code
tidy_location <- function(final_df){
final_df$Job_type <- ifelse(final_df$Location == "Télétravail", "Full Remote", ifelse(str_detect(final_df$Location, "Télétravail"), "Hybrid", "On site"))
final_df$Loc_possibility <- ifelse(str_detect(final_df$Location, "lieu"), "Plusieurs lieux", NA)
stopwords <- c("Télétravail à", "Télétravail", "à", "hybride")
final_df$Loc_tidy <- str_remove_all(final_df$Location, paste(stopwords, collapse = "|"))
final_df$Loc_tidy <- str_remove_all(final_df$Loc_tidy, "[+].*")
final_df$Loc_tidy <- str_trim(final_df$Loc_tidy)
final_df$Loc_tidy <- sapply(final_df$Loc_tidy,
function(x){
if(!is.na(suppressWarnings(as.numeric(substr(x, 1, 5))))){
return(paste(substr(x, 7, 30), paste0('(', substr(final_df$Loc_tidy[2], 1, 2), ')')))
}else{
return(x)
}})
return(final_df)
}
# Function to keep only certain words in text
keep_words <- function(text, keep) {
words <- strsplit(text, " ")[[1]]
txt <- paste(words[words %in% keep], collapse = " ")
return(txt)
}
# Homogenize the job title and class them in a few categories
clean_job_title <- function(job_titles){
job_titles <- tolower(job_titles)
job_titles <- gsub("[[:punct:]]", " ", job_titles, perl=TRUE)
words_to_keep <- c("data", "scientist", "junior", "senior", "engineer", "nlp",
"analyst", "analytics", "analytic", "science", "sciences",
"computer", "vision", "ingenieur", "données", "analyste",
"analyses", "lead", "leader", "dataminer", "mining", "chief",
"miner", "analyse", 'head')
job_titles_c <- unlist(sapply(job_titles, function(x){keep_words(x, words_to_keep)}, USE.NAMES = F))
job_titles_c <- unlist(sapply(job_titles_c, function(x){paste(unique(unlist(str_split(x, " "))), collapse = " ")}, USE.NAMES = F))
table(job_titles_c)
data_analytics_ind <- job_titles_c %in% c("analyses data", "analyst data", "analyste data", "analyste data scientist", "data analyse",
"analyste données", "analytic data scientist", "analytics data", "analytics data engineer", "data analyst engineer",
"data analyst données", "data analyst scientist", "data analyst scientist données", "data analyste", "data analyst analytics",
"data analytics", "data analytics engineer", "data engineer analyst", "data scientist analyst", "data scientist analytics")
job_titles_c[data_analytics_ind] <- "data analyst"
data_analytics_j_ind <- job_titles_c %in% c("junior data analyst", "junior data analytics", "junior data scientist analyst")
job_titles_c[data_analytics_j_ind] <- "data analyst junior"
data_scientist_ind <- job_titles_c %in% c("data computer science", "data science", "data science scientist", "data sciences",
"data sciences scientist", "data scientist données", "data scientist sciences",
"données data scientist", "scientist data", "science données", "scientist data",
"scientist data science", "computer data science", "data science données", "data scientist science")
job_titles_c[data_scientist_ind] <- "data scientist"
data_scientist_j_ind <- job_titles_c %in% c("junior data scientist")
job_titles_c[data_scientist_j_ind] <- "data scientist junior"
data_engineer_ind <- job_titles_c %in% c("data engineer scientist", "data science engineer", "data miner", "data scientist engineer",
"dataminer", "engineer data scientist", "senior data scientist engineer", "ingenieur data scientist")
job_titles_c[data_engineer_ind] <- "data engineer"
nlp_data_scientist_ind <- job_titles_c %in% c("data scientist nlp", "nlp data science",
"nlp data scientist", "senior data scientist nlp")
job_titles_c[nlp_data_scientist_ind] <- "data scientist NLP"
cv_data_scientist_ind <- job_titles_c %in% c("computer vision data scientist", "data science computer vision",
"data scientist computer vision")
job_titles_c[cv_data_scientist_ind] <- "data scientist CV"
lead_data_scientist_ind <- job_titles_c %in% c("chief data", "chief data scientist", "data scientist leader", "lead data scientist",
"data chief scientist", "lead data scientist senior", "head data science")
job_titles_c[lead_data_scientist_ind] <- "data scientist lead or higher"
senior_data_scientist_ind <- job_titles_c %in% c("senior data scientist")
job_titles_c[senior_data_scientist_ind] <- "data scientist senior"
senior_data_analytics_ind <- job_titles_c %in% c("senior analytics data scientist", "senior data analyst", "senior data scientist analytics")
job_titles_c[senior_data_analytics_ind] <- "data analyst senior"
lead_data_analyst_ind <- job_titles_c %in% c("lead data analyst senior", "lead data analyst")
job_titles_c[lead_data_analyst_ind] <- "data analyst lead"
return(job_titles_c)
}
# Function to clean the full job description before word annotation
clean_job_desc <- function(text){
text <- tolower(text)
text <- str_replace_all(text, "\n", " ")
text <- str_remove(text, pattern = "dé.*du poste ")
text <- str_remove(text, pattern = "analyse de recr.*")
text <- gsub("(?!&)[[:punct:]+’+…+»+«]", " ", text, perl=TRUE)
language <- textcat(text)
if(language == "french"){
text <- str_replace_all(text, "œ", "oe")
stopwords <- c("détails", "poste", "description", "informations", "complémentaires", "c", generate_stoplist(language = "French"))
}else{
stopwords <- c("description", generate_stoplist(language = "English"))
}
text <- str_replace_all(text, paste(stopwords, collapse = " | "), " ")
text <- str_replace_all(text, paste(stopwords, collapse = " | "), " ")
text <- str_replace_all(text, paste(stopwords, collapse = " | "), " ")
return(c(language, text))
}